概要
讃岐富士とも呼ばれる*1飯野山の形状が正規分布っぽいという説について, 本当にそうなのか, 標高データを非線形最小二乗法であてはめることで科学的に検証した.
はじめに
近年, 以下のツイートが話題を呼んでいる.
ぐぐってみると, 飯野山が正規分布ではないか, と考える人間は以前からいるようである. 正規分布ならばパラメータを持つが, 少し調べた限りでは, 飯野山のパラメータに関する研究は 著者不明の pdf のみであり, 適当に切り出した画像に対して eye-fitting, つまり目分量で曲線を当てはめ, の双曲関数の当てはまりが良いとしたものである.
飯野山に限定しないならば, 富士山の画像に対して確率密度関数を当てはめた『富士山が美しすぎたので、フィッティングをしてしまいました... - プロクラシスト』が存在する. しかしこちらの当てはまりの評価もまた目分量で合わせただけである*2.
一方, 理論モデルとしては粒状体が滑り出さない最大角を意味する安息角という概念があり, 様々な事例に対して実験による安息角の検証が行われているようだが, 山の曲線を表現できる理論モデルまでは発展していないようだ.
幸いなことに, 国土地理院のサイトから標高データをダウンロードすることができる. そこで確率分布として見た場合の飯野山のパラメータを, 非線形最小二乗法で当てはめ, パラメータの推定と当てはまりの評価をしてみる. (2019/8/26: 先行研究のサーベイを追加.)
方法
標高データはランダムサンプリングではなく, グリッド状に等間隔にサンプリングされたものなので, 最尤法で当てはめることはできない. また, 以前『[R] 東京都の所得階級分布から元の分布を推定する方法 - ill-identified diary』で書いたようなヒストグラムから元の分布をパラメトリックに推定する, という方法を2次元分布に拡張すれば応用できそうに一見思えるが, z軸の情報が頻度ではないので不可能である. そこで, 密度関数を非線形最小二乗法で当てはめる方法を考える. つまり, 経度を , 緯度を
, 標高
の観測点が
個存在するとして,
当てはめる密度関数は2変量正規分布である.
パラメータが,
と書ける (たいていの統計学の教科書には書いてあるので説明略).
しかし, 正規分布に似た形状の分布は他にもある. そこで, 2変量 t 分布と, 2変量ロジスティック分布についても当てはめてみる.
多変量 t 分布は, 例えばKotz & Nadarajah (2004), Shaw & Lee (2008) で与えられている. 2変量正規分布に合わせて書くならば, 自由度 , 位置・尺度パラメータ
に対して,2変量 t 分布の同時密度関数は以下のようになる.
今回は, 自由度 のとき, つまり2変量コーシー (Cauchy) 分布と, 自由度5の場合でのみ計算した.
多変量のロジスティック分布はあまり馴染みがないが, Gumbel (1961), Malik & Abraham (1973) で紹介されている標準多変量ロジスティック分布を参考にすると, 位置・尺度パラメータを加えた2変量の場合は,
となる (アフィン変換とヤコビアンからすぐに求められる. 多変量分布の導出については 竹村 (1991), Casella & Berger (2002) など統計学の標準的な教科書を参考に.). しかしこの定義では の相関のある場合が考慮されていない. 相関パラメータを考慮すると, このタイプの分布は非常に複雑になる (簡単にできる方法を知っている人は教えてほしい) ためだ.
しかし, 実際にこれらの関数を当てはめ, 実測値とモデル値の誤差をプロットをしてみると, 正規分布, コーシー分布でいずれも頂上付近の誤差が大きくマイナスになっている (図1). 残差がマイナスということは予測値が過大であるということなので, これらの分布と比べて飯野山は頂点付近が平坦な形状の分布なのではないか, と考えられる.
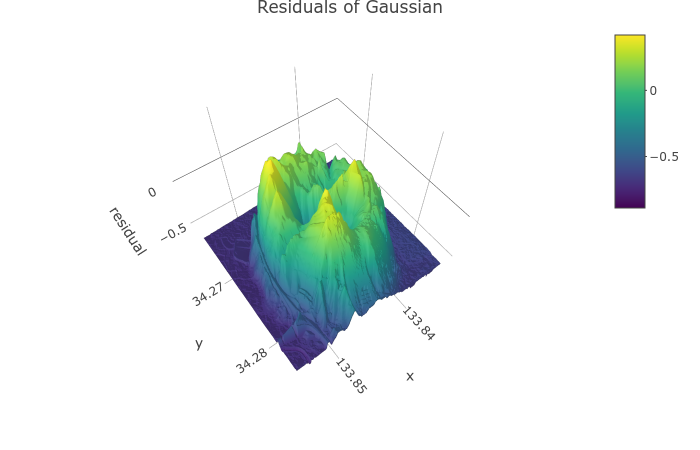
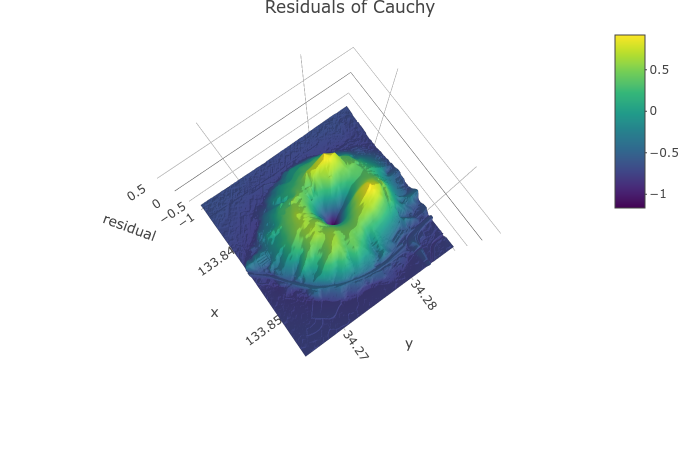
以下のページではピーク付近が平坦な分布がいくつか挙げられている.
Is there a plateau-shaped distribution? - Cross Validated
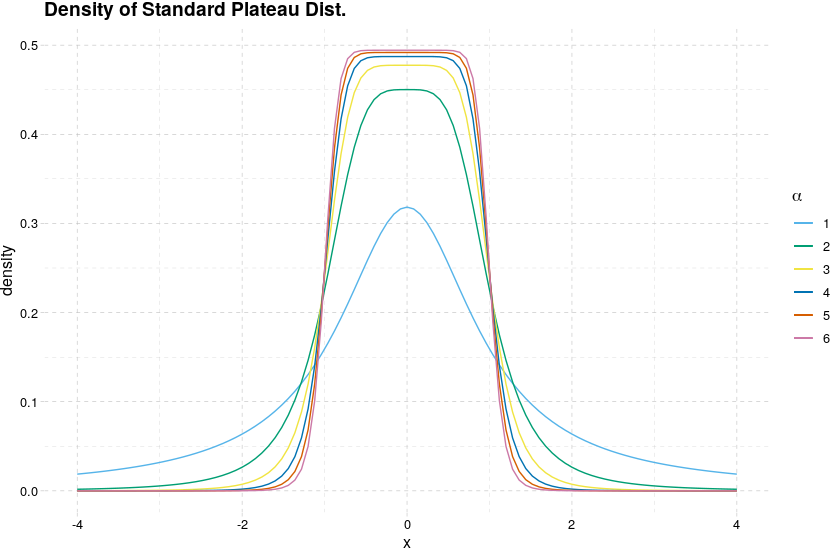
しかし, Subbotin (1923) のようないわゆる一般化正規分布をはじめ, 多くは関数が滑らかでないため非線形最小二乗法では計算できないので面倒である. そこで, この中でも非線形最小二乗法が適用可能な Is there a plateau-shaped distribution? - Cross Validated で提案されている関数を利用する. 以下, 参考ページのタイトルにならいこれを台地分布 (plateau distribution) と呼ぶ. パラメータは非負の のみである.
この分布は が大きくなるほど一様分布
に近づく (図2).
この分布に位置パラメータと尺度パラメータを追加すると,
となり, 正規分布やロジスティック分布の場合と同様に, 2変量に拡張するとその同時密度関数は,
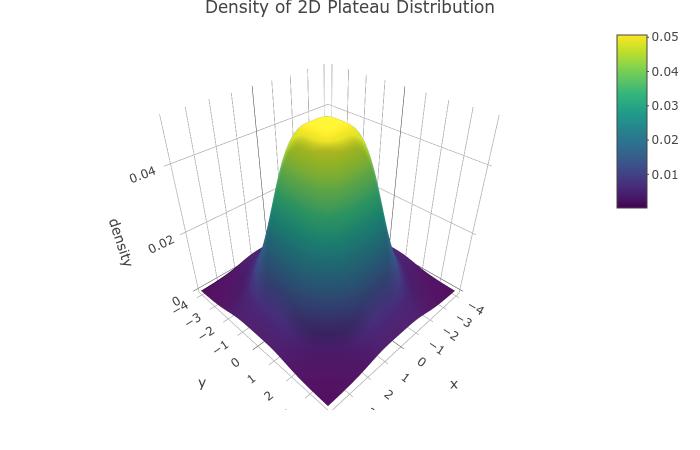
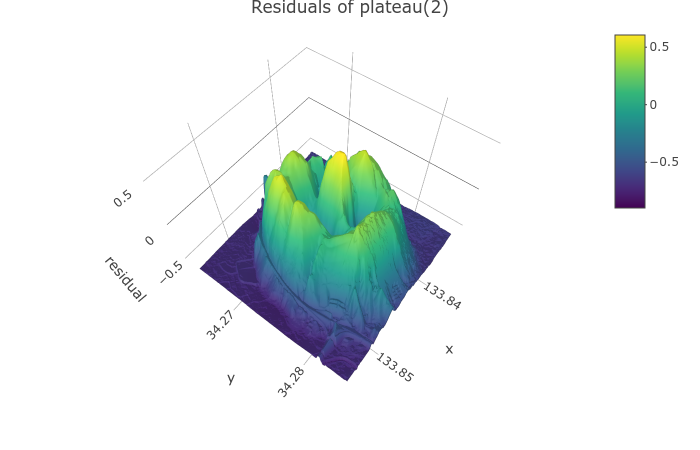
となる. こちらも相関係数を考慮すると複雑になりすぎるので, 相関のない分布を当てはめる. この分布は, のとき, 先行研究1 でよく当てはまると評された曲線と同型になる. そこで今回は
と, 頂点付近がより平坦になる
の場合を考える (図3).
実際の処理
標高データは国土地理院の基盤地図情報ダウンロードサービスから取得した. 現時点では, ユーザー登録さえすれば誰でも情報にアクセスできる.
飯野山が含まれるメッシュ番号は 513336 であり, この区画の数値標高モデルを取得した. 数値標高モデルは測量結果を5m/10mのメッシュ単位で整形したデータである*4.
ダウンロードした DEM データを R に読み込む方法は, 既に以下のサイトで紹介されていた.
国土地理院の数値標高モデルデータをラスタとしてRで扱う - cucumber flesh
このデータの構造はよくわからないのだが, いくつものファイルに分かれていてどこに何が含まれているのかよくわからないが, FG-GML-5133-36.+DEM5.+.xml でマッチする xml ファイルを片っ端から読み込めばいいらしい*5. ただし, 36A と 36B とあるファイルで, 座標が重複するため, 座標で一意になるように平均を取ることにした. このデータから等高線をプロットしたものが図 4である.
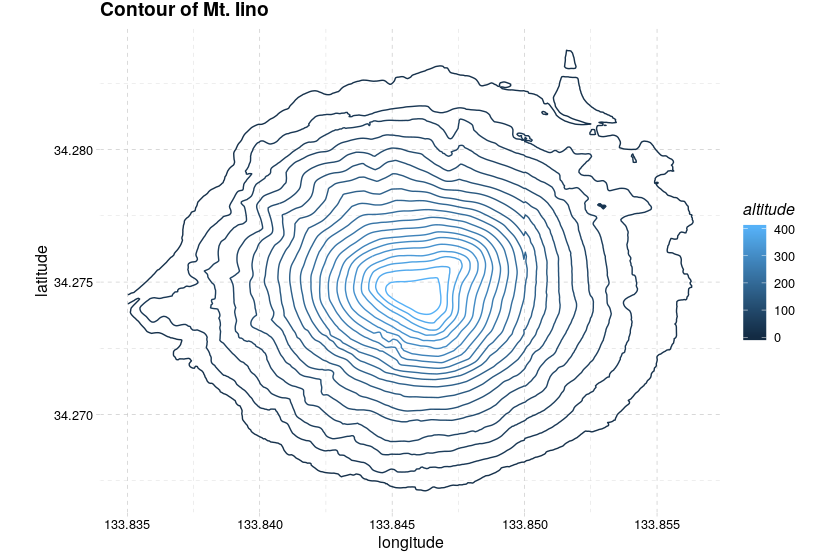
密度関数の形状は複雑で, また変数ごとにスケールも違うため, そのまま計算すると不安定となる. そのため, x, y, z 軸全てを標準化した上で計算した. よって, 計算結果をアフィン変換したものがパラメータの推定値になる.
一応解説しておく. 生データを とすると, 今回密度関数に当てはめた
は,
で与えられている. はそれぞれ生データの(標本) 平均と, 標準偏差を成分とする対角行列である:
ここで, 正規分布や t 分布で現れる変数の2次形式部分は,
と表せる. さらに, ヤコビアンは,
であることから, の位置・尺度パラメータ
は,
と表現できる. 一方で, ロジスティック分布と台地分布は積が存在しないが, 共分散も存在しないので単変量で個別に計算すれば,
となることがわかる.
プログラムは以下で公開している.
gist99c556d70f4cb99c40fb1e46a4077c28
結果と結論
パラメータの推定結果は表1のとおりである.
| name | ||||||
| Cauchy | 12.2513 | 133.8459 | 34.2747 | -0.0221 | 0.0042 | 0.0033 |
| Gaussian | 4.4604 | 133.8459 | 34.2748 | -0.0298 | 0.0028 | 0.0023 |
| logistic | 51.4076 | 133.8458 | 34.2747 | 0.0018 | 0.0014 | |
| plateau (1) | 3.1101 | 133.8459 | 34.2748 | 0.0024 | 0.0019 | |
| plateau (2) | 4.5275 | 133.8459 | 34.2748 | 0.0035 | 0.0028 | |
| Student (5) | 230.3652 | 133.8459 | 34.2748 | -0.0250 | 0.0192 | 0.0153 |
どのモデルがより当てはまっているかは, 実測値とモデル値の平均二乗誤差根 (RMSE) がより小さいかで判断した. RMSE は以下で定義される. 参考に, 平均絶対誤差 (MAE) もあわせて表2に掲載した.
表2 のように, モデルの候補の中では, 正規分布の当てはまりが最も良いという結果になった. だが, 当初の「飯野山は正規分布であるか」という問いに対しては, 「思ったほど正規分布の形状には似ていない」ということが残差プロットからわかる. 頂上付近の残差が特に大きいためだ.
加えて, 2変量間の相関が見られることもわかる. 先行研究に反して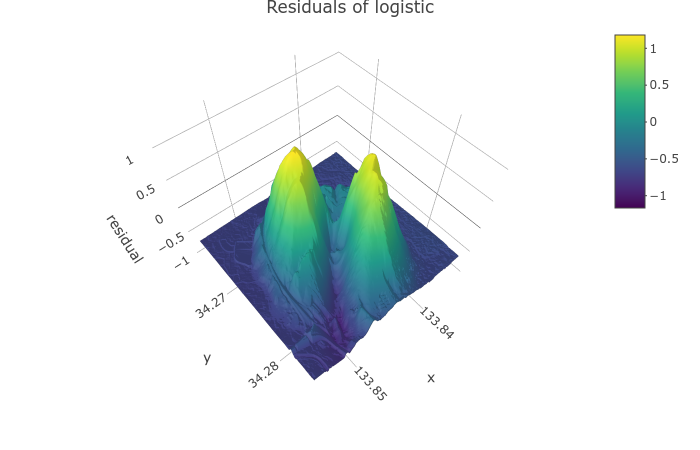
しかし, それでもなお台地分布の当てはまりが大きいということは, 頂点付近が平坦で, かつ相関のある2変量分布を作ることができればより当てはまりがよくなる可能性がある. 台地分布の台地部分は矩形に近づくため, 台地が楕円状になるようなものならより当てはまりが良くなるかもしれない (図6).
つまり, 相関係数の大きい2変量正規分布も正規分布ではあるが, 飯野山は実際には, 対称かつなめらかな「典型的な, 想像で思い描かれるような」曲線を描く正規分布とは, やや異なる形状をしていることがわかる.
| name | RMSE | MAE |
|---|---|---|
| Gaussian | 0.4859 | 0.4191 |
| plateau (2) | 0.5040 | 0.4466 |
| Student (5) | 0.5175 | 0.4629 |
| logistic | 0.5672 | 0.5177 |
| Cauchy | 0.5850 | 0.5374 |
| Plateau (1) | 0.5866 | 0.5387 |
今回は, 飯野山がどのような分布に従うか, またそのパラメータが何かということを調べた. 一方で, 地学的な観点, つまり山の風化という物理現象の理論モデルを立てる, というところからアプローチすることでその分布形状を求めることもできるかもしれない. これは今後の課題である.
参考文献
- 著者不明 (2013) 『富士山の方程式 -自然は数理を模倣する-』URL: http://www10.plala.or.jp/mondai/columun/fuji.pdf
- Casella, G., & Berger, G. L. (2002). Statistical inference. 2nd ed., Thomson Learning.
- Gumbel, E. J. (1961). Bivariate Logistic Distributions. Journal of the American Statistical Association, 56(294), 335. doi:10.2307/2282259
- Kotz, S., & Nadarajah, S. (2004). Multivariate t distributions and their applications. Cambridge ; New York: Cambridge University Press.
- Malik, H. J., & Abraham, B. (1973). Multivariate Logistic Distributions. The Annals of Statistics, 1(3), 588–590. doi:10.1214/aos/1176342430
- Shaw, W., & Lee, K. (2008). Bivariate Student t distributions with variable marginal degrees of freedom and independence. Journal of Multivariate Analysis, 99(6), 1276–1287. doi:10.1016/j.jmva.2007.08.006
- Subbotin, M. F. (1923). On the Law of Frequency of Error. Matematicheskii Sbornik, 31(2), 296–301. Retrieved from http://mi.mathnet.ru/eng/msb6854
- 竹村彰通. (1991). 現代数理統計学. 創文社.
*1:https://www.shikoku.gr.jp/spot/387
*2:この記事の著者は最尤推定で当てはめたと主張しているが, 本文で後述する通り, 画像に対するガウシアン曲線の当てはめであり尤度に基づいた最尤推定ではない. 対称なガウシアン曲線を平均 (または中央値) ・標準偏差を標本値に基づいて調整し位置を揃えただけである.
*3:そうでなくとも、植生によって見た目の曲線と実際の標高に差がある可能性もある
*4:そもそも, どこまでを山とするかと言う問題はある. 理論上は正規分布の裾野は無限に広がっているが, 観測データは無限ではない. しかし, 今回対象となる飯野山は, 周囲が開拓され平坦である. そのため, メッシュデータに現れないほど低い標高の場所は山ではないという扱いとした.
*5:数値標高モデルでなくポリゴンデータとしても提供されているが, グリッド状に変換するのが面倒なので使わなかった