概要
- 以前にも書いたように Python の pandas は参照透過性に欠けるため, 何度も書き換えて使用するような使い方に向いていない. これは pandas の用途と合わない.
- pandas をもっと快適にデータハンドリングする方法がないか探したところ, siuba, datar というパッケージを見つけたので紹介する.
- これらのパッケージの特徴を挙げ, 実験によるパフォーマンス比較してみた.
- 個人的には siuba のほうが信頼できると思うが, 現時点ではどちらも発展途上のパッケージである.
- 以前の続きということでタイトルを踏襲したが, 実は私がこれらのパッケージを知ったのは昨日なので「実践」的かどうかは少し疑わしい
- タイトルの通り R を知っている pandas ユーザーを想定読者としているが, R ユーザでなくても再利用のしやすい書き方は知っていて損はないと思う. その場合は実践ガイドその1を先に読めばよいだろう.
はじめに
Python でも R の tidyverse のように簡単な操作でデータフレームを加工したいが, pandas は tidyverse ほど構文が整備されていないのが実情である. pandas を使用した R ユーザはたぶんこういった不満を持つのではないだろうか?
- 参照透過性がない
- グループ化後の列変換がやりづらい
groupby()の後にassignやevalを使えない (transformで代用できないこともないが使いづらい)
- long to wide/wide to long のピボット変形がやりづらい
- tidyr のように関数1つで変形することができないことがある.
- index がはっきり言って邪魔
- index が役に立つ場面は限られている一方で, データフレームの結合時に意図と違う挙動をするなど不便な場面が多いため頻繁に
.reset_indexを呼び出すことを強いられている
- index が役に立つ場面は限られている一方で, データフレームの結合時に意図と違う挙動をするなど不便な場面が多いため頻繁に
この問題のうち (1) はある程度解決できることを, tidtverse を使い慣れた R ユーザを想定読者にして, 以前書いた. R の dplyr のような API を pandas をバックエンドに使えるようにしたパッケージとして, dfply が存在するものの, あまり使い勝手が良くないことはその時にも書いた. 他にもdplython という似たパッケージがあるが, これらはここ数年更新されていない. しかしわりと最近になって似たコンセプトのパッケージが2つ登場した. それが siuba と datar である. 今回はこの2つを紹介したい.1
各パッケージの紹介
Siuba について
siuba は現在 dplyr とパイプ演算子, そして tidyr に対応する関数を主に用意している. このパッケージの大きな特徴は以下の2点だろう.
- pandas だけでなく SQLAlchemy にも対応している (ただし今回は SQLAlchemy の機能は確認してない)
- dplython の API 設計を踏襲しつつ, このパッケージの処理が遅かった部分を改善している
なお, siuba という名前は「小巴」に由来する. 香港で運行しているマルシュルートカみたいなもの?らしい. dplyr等のRパッケージを使った処理フローを路線に見立てているのだろうか?
siuba はだいぶ tidyverse に近い書き方ができる. 例えば公式ドキュメントでは冒頭に以下のコードが紹介されている.
from siuba import * from siuba import _ as X from siuba.data import mtcars (mtcars >> group_by(_.cyl) >> summarize(avg_hp = X.hp.mean()) )
## cyl avg_hp ## 0 4 82.636364 ## 1 6 122.285714 ## 2 8 209.214286
これは R での以下のコードに対応する.
require(tidyverse) data(mtcars) mtcars %>% group_by(cyl) %>% summarize(avg_hp = mean(hp), groups = "drop")
なお, Python 構文の仕様上, 今回紹介するパッケージはいずれも R のようにパイプ演算子の直後で改行することはできない. ただしサンプルコードのようにタプル内であれば可能である.2
siuba の構文は dplython を参考にしている. dplython が X というオブジェクトを使って dplyr の遅延評価を擬似的に再現しているように, siuba では _ というオブジェクトを使用する. pandas データフレームの列を参照するとき, 自分自身名の再起的な参照を避けるために lambda を使う必要があったが, それは以下のように置き換えられる.
# 古い方法: データフレーム名を繰り返さねばならない mtcars[mtcars.cyl == 4] # 古い方法: lambda を使う mtcars[lambda _: _.cyl == 4] # siu の方法 mtcars[_.cyl == 4]
個人的には _ にその役目を負わせるのはあまり好ましいとは思えない (グラフ描画関数の不要な標準出力を捨てるときに使う, 多用することが予想されるのに小指を伸ばさないと打てない)3. これが問題なら別の名前にリネームすればよいだけではあるが.
User API によれば, mutate, group_by, arrange, select といった基本的な関数は全て用意しているようだ. full_join, anti_join,4 semi_join も用意されている.
さらに, 列選択は dplyr::select のように, 列インデックスや名前, あるいは dplyr::starts_with と同等の _.startswith() などいろいろな指定方法が可能である.
select(mtcars, _['mpg':'disp']) select(mtcars, _[:]) # 全列 select(mtcars, _.startswith('a'))
filter も本家のように, filter(条件1, 条件2, ...) という書き方ができる. pandas 単体で似たようなことをするには,
mtcars.loc[lambda d: (d.x == ...) & (d.y > ...) & (...)]
のように書かなければならなかったので, だいぶシンプルになるだろう. もちろん group_by に続けて実行することもできる. 以上から, (1) の問題はだいぶ改善されている. ただし, across() などの dplyr v1.0 以降の新機能・挙動に対応するものはなく, mutate_all, mutate_at, mutate_each に対応する関数もないため, 複数列を対象にした変換・集計はやや不便である. あと集計関数は summarize の方しかない (summarise がない, これは dplython を踏襲したため?) ので注意.
2番目の問題も, group_by 後に mutate や filter を使うことができる. ただし直後に ungroup を呼び出さないと結果が表示されない
3番目の問題について, tidyr に対応する関数として nest, gather, spread がある.
4番目の問題についても, 公式ドキュメントで長所として取り上げているように, 結合や集計など pandas が勝手に列をインデックスに移動していた挙動はなくなっている.
よって, siuba は冒頭に挙げた pandas の不満点4つをいちおう全て改善していると言える.
その他, dplyr の関数である if_else と case_when (ソースコードを見るとまだ作りかけらしいが) も一応用意されている. case_when はどうやら 条件: 値 のディクショナリを与えればいいらしい.
mutate(mtcars, new=case_when({(_.mpg>20) & (_.cyl>6): 'A', _.mpg>=20: 'B'}))
## mpg cyl disp hp drat wt qsec vs am gear carb new ## 0 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 B ## 1 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 B ## 2 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 B ## 3 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 B ## 4 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 None ## 5 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 None ## 6 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 None ## 7 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 B ## 8 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 B ## 9 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 None
datar について
datar はかなり最近になって作られたもの. siuba より更に野心的で, tidyverse のいろいろな関数をそっくりな構文で使えるようにするという目標を掲げていおり, tidyverse 外の関数でもいくつかは利便性のために取り入れている. たとえば tibble や, across のような最近の tidyverse の更新も反映している.
ただし, 素の Python プロンプトではパイプ演算子が動作せず, ipython や jupyter 上でないと動作しないという制約がある (= reticulate や vscode では使いづらい, Pycharm は追加の設定なしで使用可能). これはパイプ演算子を提供する, 同一開発者による pipda パッケージの制約である. v0.4.3 からは以下のようにオプションを設定することで ipython でなくても使用できる5 と書いているが, しかし逆に, datar が提供する全ての関数について引数をパイプで渡さないとうまく動作しなくなり, datar 関数のネストが深くなるとパイプが必要な箇所が分かりづらくなる.
from datar.all import *
## [2021-09-18 12:51:29][datar][WARNING] Builtin name "min" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "max" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "sum" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "abs" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "round" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "all" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "any" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "re" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "filter" has been overriden by datar. ## [2021-09-18 12:51:29][datar][WARNING] Builtin name "slice" has been overriden by datar.
from pipda import options options.assume_all_piping = True
上記の ... import * は全ての関数をロードすることができるが, 構文を R に近づけるために pi とか FALSE とかいろいろなものがロードされるので競合に注意する必要がある. この状態で, 以下のようなコードが動作する. siuba の _ に対応するものは datar では f である.
df = tibble(
x=range(4),
y=['zero', 'one', 'two', 'three']
)
df >> mutate(z=f.x)
## x y z ## <int64> <object> <int64> ## 0 0 zero 0 ## 1 1 one 1 ## 2 2 two 2 ## 3 3 three 3
出力も tibble のように各列の型が表示される.
siuba の _ に対応する f が必要であることと, パイプ演算子が >> であること6は siuba と変わらないが, かなり R に近い書き方ができる. 例えばピボット変形は tidyr v1.0.0 以降の pivot_longer/pivot_wider が用意されている.
mtcars >> pivot_longer(cols = everything())
dplyr v1.0 以降の across や where, そして everything() など tidyselect の関数に対応したものも用意されている.
(
mtcars >>
mutate(across(c(f.mpg, f.drat), round)) >>
head()
)
across の強みである複雑な条件での列選択もわりと近いことができる.
mtcars >> mutate(across(where(is_integer) & c(f.mpg, f.disp), round)) >> head()
このように, tidtverse の構文にかなり似せてあるため, datar も (1 - 4) の問題を全て解決している.
処理速度の比較実験
dfply は素の pandas より遅かったが, siuba や datar はどうだろうか?
まずは公式ドキュメントでの言及. siuba の公式ドキュメントでは, filter や group_by など dplython の関数では遅くなりがちだったところを, 実験的に高速化した (100倍くらい速くなったと自称している) fast_* で始まる関数群を用意したと書いてある.
datar の Performance のページでは, group_by のオーバーヘッドが大きく素の groupby よりもだいぶ遅くなっている一方, 集計処理はわずかに早くなる場合もあるというベンチマーク結果が掲載されている.
比較のため, 条件をなるべく揃えて dfply, dplython, siuba, datar の処理速度を比較してみる. 上記の公式ドキュメントでの記述を参考に, 以下の処理について速さとコードの文字数を調べてみた. (コードの文字数は変数名の長さと参照透過性をどの程度保証できるかで変わってくるので一般化するのは難しいが…)
- sorting: 10列のソート
- filtering: 3列で条件づけたフィルタリング
- mutation: 10列の列単位の変換
- grouping: 3列のグループ化
- summarizing: 10列の集計
- group-summarizing: 3列でグループ化した後残り列を集計
- group-mutation: 3列でグループ化した後残り列を mutate で変換
- wide-to-long: wide-to-long なピボット変換
- long-to-wide: long-to-wide なピボット変換
最後の long-to-wide を除いて, それぞれ 10万行10列のデータフレームを, 最後の long-to-wide はこれを100万行のlong形式にしたものを渡して元のデータフレームに復元する処理を100回づつ繰り返し試した. ただし, dfply と dplython は独自のピボット変換メソッドを用意していていないため pandas と同じコードを使用している.
以下が実行時間を箱ひげ図で示したもの.
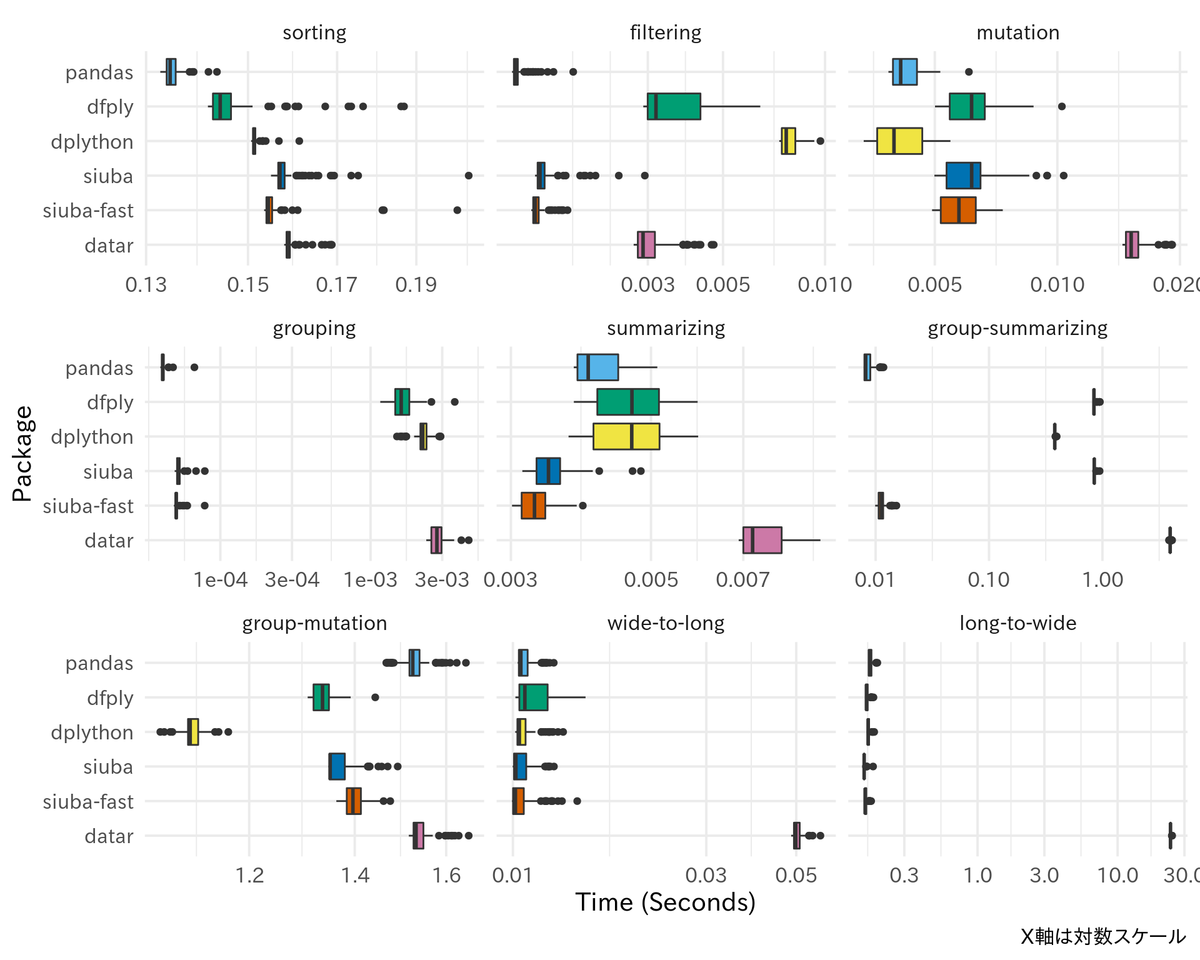
一部の処理は特に datar が極端に遅いため, datar を除外して比較したものも掲載する.
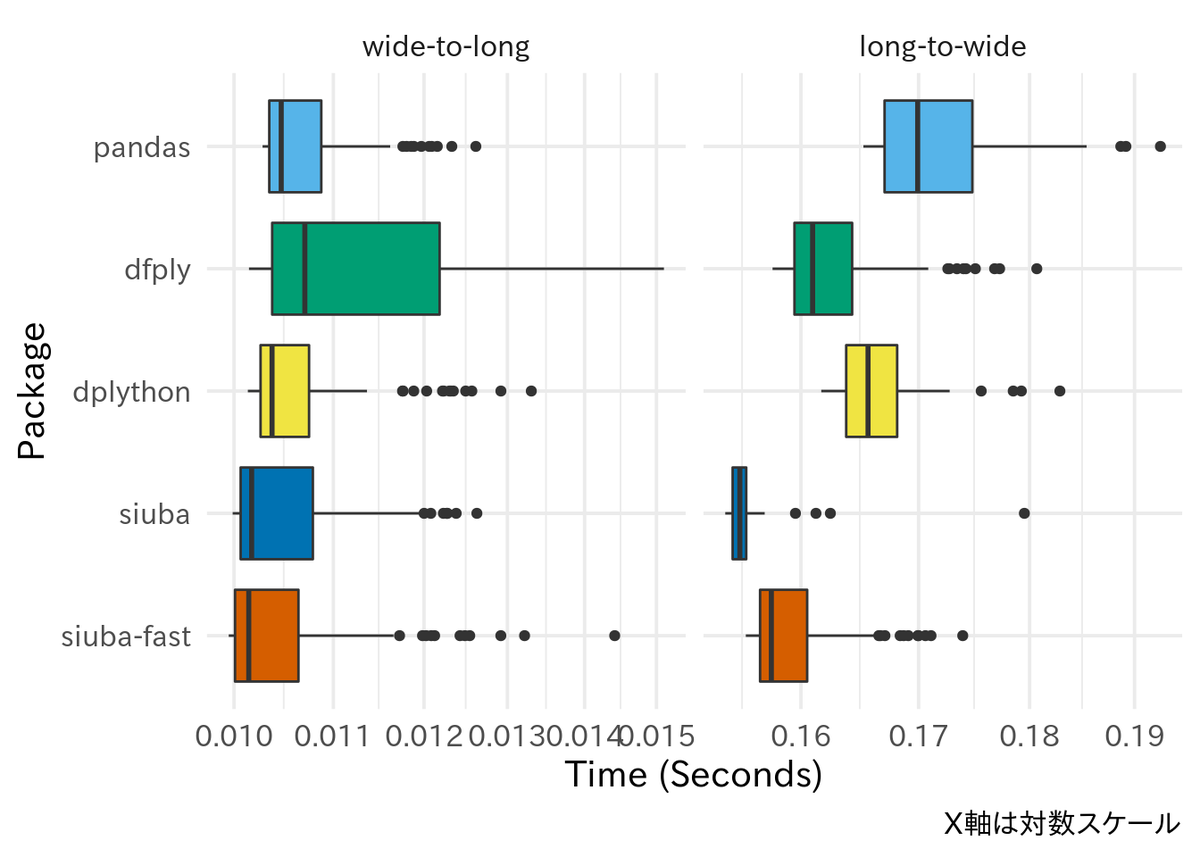
siuba は公式ドキュメントで言及されているように, 高速化版関数を使うと dplython が特に時間のかかっている filtering, grouping, group-summarizing の処理が早くなっているのがわかる (特に filtering は主張しているように100倍近い差がある). ただし, group-mutation のみ dplython が最も速い. また, 高速化版関数はグループ化時の処理を想定しているためか, グループ化していない filtering や mutation では僅かだが速度が低下しているようにも見える. しかし, 全体として pandas と比べてどの処理も非常に速いというほどではない. 2種類のピボット変換はいずれも, dfply, dpython は pandas のメソッドを使っているはずだが, 処理速度に違いが見られる. プロファイルを細かく見ていないのでどこで差が現れるのかはよくわかっていない. datar は全体的にかなり遅い.
最後に, 文字数は以下の通り.
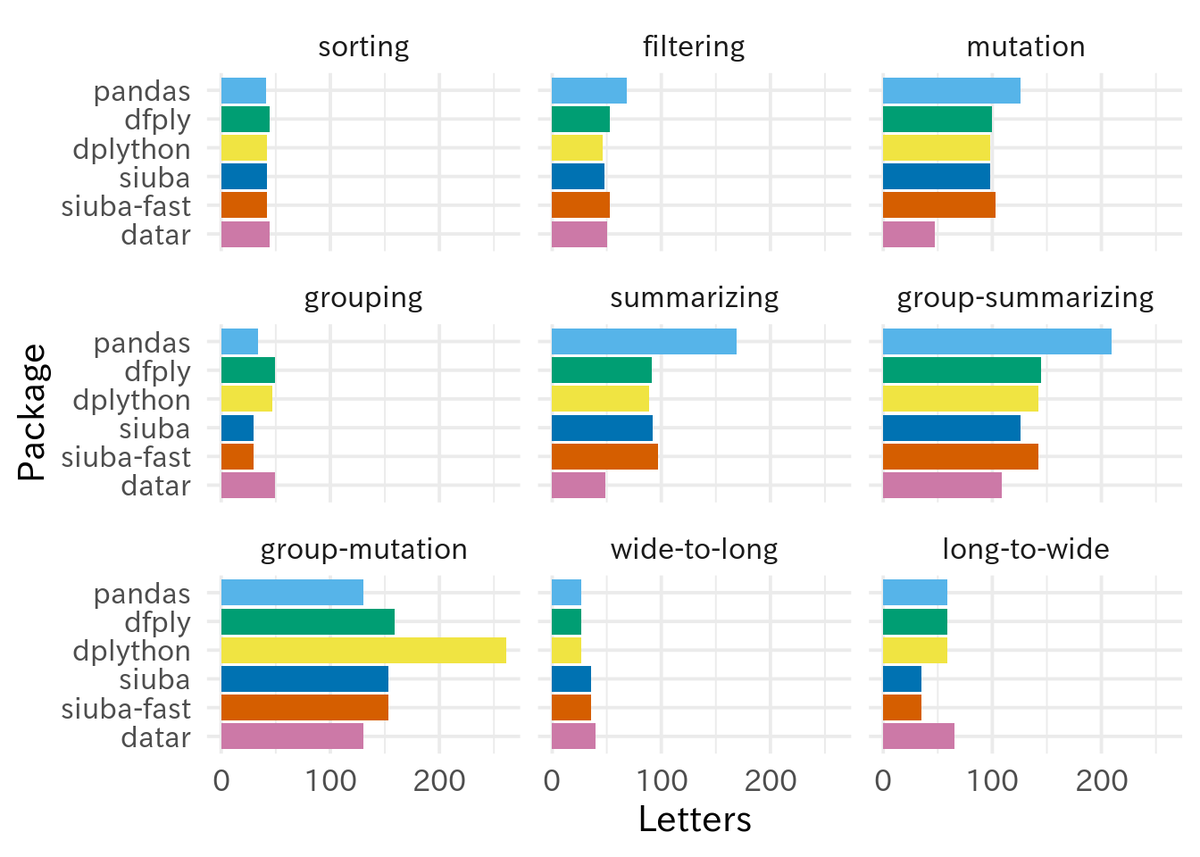
処理が込み入っているものほど, pandas の文字数の多さが目立つ. そして込み入った処理ほど tidyverse の構文を真似た datar がシンプルなコードで済ませられるようになる. wide-to-long/long-to-wide で文字数が若干多くなっているのは, pivot_longer/pivot_wider が採用されているからだろう (関数名や引数名でも結果が左右されてしまうということからも, 今回のような文字数の比較方法はあまり一般性がないことがわかる). dfply, dplython, siuba は見かけ上の構文が似たりよったりであるため, 今回の実験ではあまり文字数で差がついていない.
結論
siuba は従来の類似パッケージでは解決していない速度の問題を改善している. しかし, 列選択の構文はあまり改善していない. 一方で datar は tidyverse にかなり似せた構文が使用できるが, (末尾の補足に書いたように) 必ずしも完全ではなく, また pure Python REPL では満足に動作せず, pandas や他の類似パッケージと比べかなり実行速度が低下する, と一長一短である. 短時間だが使ってみた体感では, siuba のほうが意図に反する挙動が起こりにくい気がするため, こちらのほうが信頼できそうな気がする. ただし実際には高速化関数が実験段階だったり, ドキュメントが整備されていなかったりするので作りかけ感が否めない. その点 datar は最近頻繁に更新されているので, 近いうちに処理速度が改善されるかもしれない. これら2つのパッケージの残された問題点は今後の更新に期待 (月並な感想) ということで, なにかにつけて reset_index をいちいち呼び出さずに済む, ピボット変換が簡単になった, という点だけでもかなり使いやすさが改善されているので, pandas の構文の乱雑さに不満のある人は使ってみてはどうだろうか?
siuba の公式ドキュメントに pandas と dplython との比較表7があるので, datar を追加して掲載してみる.
| siuba v0.0.25 | dplython v0.0.7 | dfply v0.3.3 | datar v0.5.0 | pandas v1.3.3 | |
|---|---|---|---|---|---|
| pandas.Series のメソッドでの列操作 | ✅ | ✅ | ✅ | ✅ | ✅ |
| ユーザー定義の表を操作する関数のサポート | ✅ | ✅ | ✅ | ✅ | ✅ |
| パイプ演算子 | ✅ | ✅ | ⚠ | ⚠ | ❌ |
簡潔な遅延評価 (例: _.a + _.b) |
✅ | ✅ | ✅ | ✅ | ❌ |
| reset_index の撲滅 | ✅ | ✅ | ✅ | ✅ | ❌ |
| グループ化・非グループ化データフレームの API 共通化 | ✅ | ✅ | ✅ | ✅ | ❌ |
| 高速なグループ化処理の生成 | ✅ | ❌ | ❌ | ❌ | ✅ |
| SQL クエリの生成 | ✅ | ❌ | ❌ | ❌ | ❌ |
| 変換操作の抽象構文木 | ✅ | ❌ | ❌ | ❌ | ❌ |
| ネストデータの操作 | ✅ | ❌ | ❌ | ✅ | ⚠ |
| dplyr v1.0 以降の列選択構文 | ❌ | ❌ | ❌ | ✅ | ❌ |
補足: 実験に関する注意点
以下は実験に関するいくつかの細かい注意事項である.
- 実験に使用したコードは github にアップロードしてある. Python 本体は v3.9.6 を使用した.
- 処理は全てワンライナーにおさまるように書いた.
- なるべく変数名の数や長さや各パッケージの機能と関係ない部分に依存しないように, 複数列を選択する場合はリスト内包表記を使うなどしてコーディングにしたつもりだが, 結果として, 普通の人は書かないような可読性の低いコードになっているかもしれない.
- 実験に使用したコードでは平均や四捨五入など簡単な処理をしているが, なるべく他の関数に置き換えても動作するようなコードをめざした.
- 出力が一致するように, インデックスが変更される pandas の処理は全て最後に
reset_indexを呼び出すなどして調整している. - pandas は, mutation で
assignを使用している.assignよりevalのほうが効率的だが,evalは使える関数がかなり限定的なので一般的なケースでの参考になるようにassignの処理時間を計測した.8 - pandas は
groupby後にassign,evalを呼び出せず,transformは列単位での処理をすることができない. - dpython は, 入力を
pandas.core.DataFrameではなく独自クラスdplython.dplython.DplyFrameにする必要があるが, pandas のデータフレームにあるようなエクスポート用のメソッドを持っているので, 最初からDplyFrameに変換されているという想定とした. よってこの変換のオーバーヘッドは実験結果に反映されていない. - dplython は group-mutation においてリスト内包表記で変数名と処理を与えると再帰呼び出しエラーとなったので列名をハードコーディングした. このため他の候補と条件が揃っていないが, おそらくパフォーマンスには大きな影響はない.
- siuba の「高速なグループ化処理」というのは, どうやら実験的に導入されている
group_by使用時の処理速度を向上させたfast_で始まる関数群によって実現できるらしい. よってこれらを使用しないものと, 使用しないもの (“siuba-fast”) の両方を比較した. - siuba には公式ドキュメントに書かれていないものの
fast_summarize, という関数があったため使用してみた. しかしこの関数はgroup_byと組み合わせた際に使える集計関数に制約があるようだ. 同様にfast_mutateもgroup_byと組み合わせた場合うまく動作しなかったので, siuba-fast の group-mutation では通常のmutateを使用した. datar は,. よって pandas と同じコードを実行した.group_by後にmutateが使えるかのように書いてあるが, 現時点ではグループ変数が2つ以上になるとグループ化変数が2つ以上で, かつグループごとの件数が異なる場合に, 正しく処理できずエラーが発生する
追記: 開発者にこのブログを補足されたので問題を投稿したところv0.5.3で修正された (https://github.com/pwwang/datar/issues/63). ベンチマーク結果は未確認.
さらには pandas-ply とか, ごく一部の機能 (パイプ演算子とか) だけ再現しようとしたものも見かけたが今回は紹介を省略↩︎
実は自分も最近までこれを知らなかった.↩︎
加えて knitr もどうやら
_を内部で使用しているらしく, reticulate と併用していると結果がうまく表示されないようだ.↩︎ドキュメントでは “TODO: implement” などと書かれているがたぶんもう実装されている↩︎
https://github.com/pwwang/datar/issues/45#issuecomment-892269117↩︎
ただしこの表は experimental な高速版関数をカウントしているわりに, これでは一部の pandas.Series メソッドが使えないことを項目に反映していない. https://siuba.readthedocs.io/en/latest/key_features.html↩︎
よってデータフレームのサイズに対し物理メモリがとても少ない状況ではあまり参考にならない. しかしそのような状況だとそもそも out-of-core な処理が必要である可能性が高く pandas 単体でもできないと思われる.↩︎