- 要約
- はじめに
- GLM の特殊形としてのロジスティック回帰
- 潜在変数モデルとしてのロジスティック回帰
- 機械学習の分類モデルとしてのロジスティック回帰
- 事後確率の近似としてのロジスティック回帰
- (追記) 多項選択・多クラス分類への拡張
- 参考文献
いまさらロジスティック回帰?と思うかもしれないが, もう火鍋の話はしない. 昔書いたやつを読み返したら中途半端だったので改めて(2値)ロジスティック回帰のいくつもある表現について書きたくなった. 昔書いたやつというのは以下のことである.
要約
今度は以下の4種類に触れる. 最初の2つは前回の記述を推敲しただけでほとんど同じである.
- 経済学でよく使われるロジットモデルの潜在変数モデルによる表現
- 一般化線形モデル (GLM) の特殊形としてのロジスティック回帰
- 機械学習の分類タスクとしてのロジスティック回帰 (分類) モデル
- 事後確率で見たロジスティック回帰
各教科書に載っている内容を集めただけなので, 目新しい話はない.
はじめに
最もシンプルなモデルであるロジスティック回帰には, いくつもの表現がある. どのモデルでも得られる結果は同一だが, 導出の過程が異なる.
GLM の特殊形としてのロジスティック回帰
久保 (2012) (緑本と呼ばれるあの本) では, 線形予測子をロジットリンク関数で変換したものとしてロジスティック回帰を解説している.1 線形予測子 を次のように定義する. これ以降の定式化と比較しやすいよう, 本誌の記述とは異なる記号で統一していることに注意してほしい.
はそれぞれ説明変数で,
がパラメータである. GLMでは, 線形予測子を変換する関数をリンク関数はと呼んでおり, ロジットリンク関数とはロジスティックシグモイド関数 (以下, 単にシグモイド関数と呼ぶ)のことである.2 線形予測子をシグモイド関数で変換した
は以下のようになる.
となる. シグモイド関数は, の定義域に対して
の値域への変換ができる. つまり, シグモイド関数によって線型予測子を確率として扱える.
を
の確率とおきかえると,
がとる値は二項分布になる. これをもとに尤度関数を作成すると,
となる. しかしながら, 久保本は が 0, 1 以上の値を取る場合の式を書いている. 厳密には, GLMの定義では, 上記の二項分布の式がロジスティック回帰と呼ばれる3ため, 後述する計量経済学と機械学習での定義とは少し異なる. しかし今回は2値のロジスティック回帰のため,
がゼロか1しかない場合だけを考える.
も1になるので, 二項分布の最も単純な形式であるベルヌーイ分布となり, 尤度関数はもう少しシンプルに, 以下のように書ける.
対数尤度関数は以下のように表せる.4
潜在変数モデルとしてのロジスティック回帰
計量経済学においては, ロジスティック回帰はロジットモデルと呼ばれることが多い. そして教科書ではロジットモデルを説明する時, 多くの場合で潜在変数 (latent variable) モデルを用いて表現している. 潜在変数とは, 結果を表す変数が直接観察できないという意味である. 経済学では, 人間の意思決定は効用関数で数量的に表現できるが, 多くの場合で効用関数は直接観測できないという想定で理論分析を行っている. 基本的なロジスティック回帰では, 効用は線型回帰と同じように, 説明変数に依存して決定すると仮定している. ここでは, 記法の統一のため, 誤差項を含まない部分のみを としている. しかし, 一般に潜在変数は誤差項を含んだものと定義される. つまり,
までが潜在変数となる. 多くの教科書では誤差項も含んだ式を
と表記するため, 注意が必要になる.
ロジットモデルでは, この効用の大きさが本来の結果変数だが, 効用は観測はできない潜在変数であり, 行動として現れる ゼロか1かの2値の離散変数 を代わりの被説明変数として扱う.
潜在変数である効用を と表すと, 行動として現れる結果変数
のどちらを選ぶかの意思決定が, ゼロを境に決まると仮定する.
ここで, は誤差項で, 標準ロジスティック分布にしたがうと仮定する. 標準ロジスティック分布とは, 位置パラメータがゼロ, 尺度パラメータが1のロジスティック分布のことで, 累積分布関数は以下で与えられる.
よって, である確率, つまり選択確率は, それぞれ以下のようになる.
潜在変数と説明変数の関係式と合わせると, この選択確率はGLMのロジット と同じであるとわかる.
さらに, ロジットモデルの尤度関数は, 選択確率が背反であるから, 2つの選択確率の積で表せる. よって, 尤度関数もGLMでのロジスティック回帰と同じになる.
ロジットモデルはこのように, 効用関数の概念を類推しやすい定式化から始まって, ロジスティック回帰と同じ式に帰着している. 効用 が一定以上高ければ, 実際の行動
として現れ, 逆にその行動から得られる効用
が小さければ,
という行動, 言い換えるなら「行動をしない」 という選択に現れる. そして, その効用を決定する要素が説明変数である. ある商品を買う (
) か買わない (
) かを決めるのは, その商品の価格や品質, あるいは消費者の好みで決まると考えると, これらが説明変数に対応する (これは混合ロジットモデルと呼ばれる). さらに, 潜在変数モデルの考え方は多項選択モデルへ拡張することもできため, 多項ロジスティック回帰でも同じ要領で定式化できる. 詳細は, 昔書いた話 (https://ill-identified.hatenablog.com/entry/2014/06/10/000354) や, より専門的な話が知りたければ, Train (2009), Wooldridge (2010) などがおすすめである.
なお, 個人レベルの意思決定のデータがなく, 大勢の意思決定をいくつかのグループに集計したものだけが使える時に, そのグループ内で何割が選択している, という割合を被説明変数にした回帰モデルを集計ロジットモデルというらしい. 私は知らなかったが, 交通政策の分野なんかで使われることがあるらしい.
機械学習の分類モデルとしてのロジスティック回帰
機械学習でよく用いられる, 分類問題としてマージンから損失関数を構成する定式化を紹介する. 例えば 杉山 (2013), 中川 (2015) では, この定式化で説明されている.
まずは, ロジスティック回帰の定式化の前に, マージンと損失 (loss) の考え方を導入する. ここまでで紹介した2つのロジスティック回帰とは違い, 機械学習の2値分類問題では結果変数を の2通りと定義することが多い. しかし,
から
への変換は
で簡単にできるため, 本質的な問題とはならない.
を正しく分類するモデルを作るためには, 誤まって分類した時は1を, 正しく分類したときは0を返す関数を考える. 最尤法では尤度関数を最大化することでパラメータが決まるが, 機械学習では損失関数を最小化することで決まる.
線形分類モデルでは, マージンは, ラベルと線型回帰モデルの右辺の積で表される. ここで, これまでのロジスティック回帰の代数との混同を避けるため, ラベルを と表すと, マージンは以下のようになる.
機械学習では, 分類問題を, 誤った時の損失を最小化する問題として定式化する. ラベルは-1か1のどちらかなので, との積であるマージンが正ならば分類が正しいということになるから, 以下のような損失関数が考えられる. これを 0/1損失と呼ぶ.
ここで, は, 以下で定義される.
しかし, このような損失関数は非連続であり, 組み合わせ最適化問題に属するため, 現実的に計算できない可能性が高い. そこで, 機械学習では0/1損失を近似できて計算しやすい関数で置き換える. そのうち1つがロジスティック損失あるいは対数損失と呼ばれる損失関数で近似したロジスティック回帰であり, あるいは2乗損失を利用した最小二乗法であり, ヒンジ損失を使用したサポートベクターマシン (SVM) であり, 指数損失を利用したAdaBoostであったりする. こういった損失関数は代理 (surrogate) 損失という. この中ではロジスティック損失は と定義される.
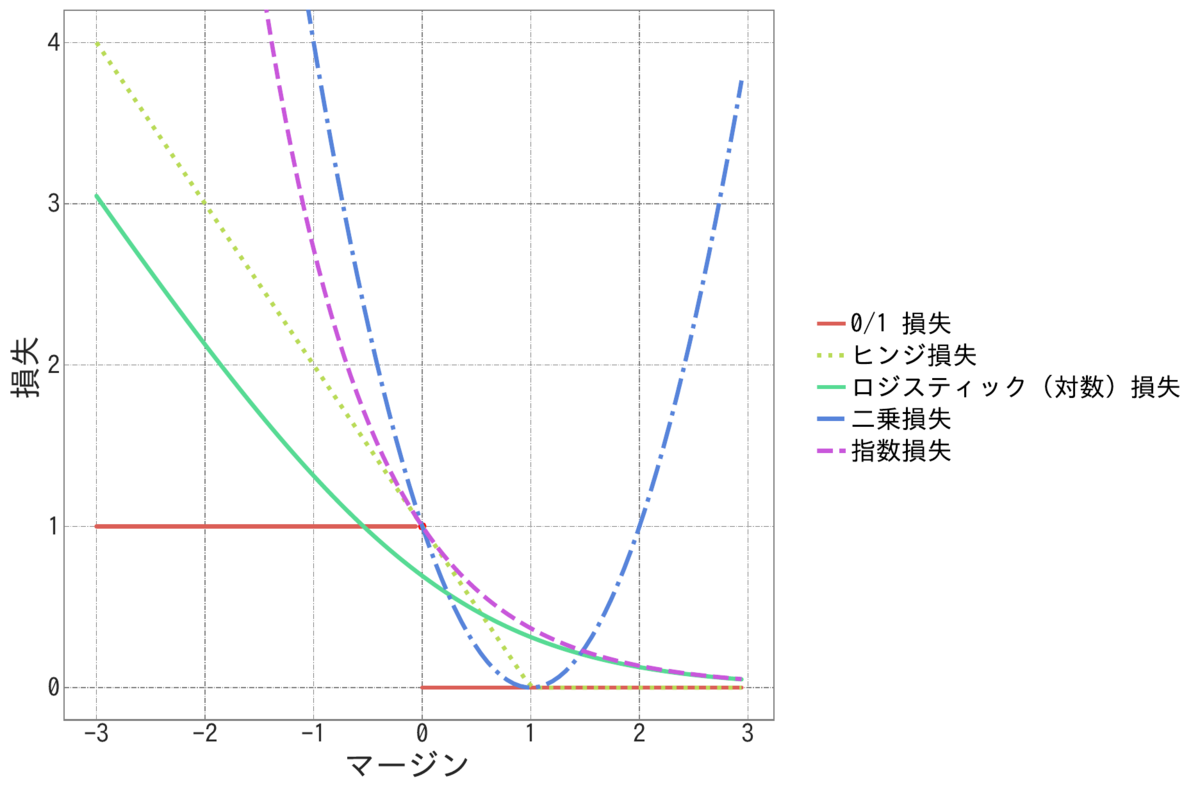
に対応するラベルは
なので, 確率は
と表せる. 同様に
, つまり
のとき,
と表せるので, この表記での対数尤度は以下のように表せる.
対数尤度が, 符号が反転したロジスティック損失となった. 機械学習では損失関数を最小化するから, これは対数尤度の符号を反転して最大化することと同じである. よって, この式から, ロジスティック回帰の対数尤度最大化とロジスティック損失最小化が等価であることがわかる.
事後確率の近似としてのロジスティック回帰
Bishop (2006) の Pattern Recognition and Machine Learning, いわゆる『パターン認識と機械学習』は機械学習の名を冠しているが, 上記のようなマージンを使った説明ではなく, 事後確率を使用して導出している.5
なお, 上の式では事後確率は本来 で条件付けられるべきだが, 冗長なので
は省略する.
とおくと, 事後確率は以下のようになる.
ここで, は, データのうち各
に属するものの特徴量
の条件確率である. この
の条件分布が正規分布だと仮定するなら, 以下で表せる.
ここでさらに, 各ラベルの標準偏差 が等しく
だと仮定すると,
,
は
と表せる. よって, ここでも線形予測子とシグモイド関数の関係が現れる.6
以降の尤度関数を構成する箇所は, GLMやロジットモデルと同じなので省略する.
この説明は一見すると, 導出仮定がややこしく, 式は複雑で洗練されておらず, いびつに見えるかもしれない. しかし, ここまでの3種類の説明では, 事前確率 にあたる要素に全くふれられていなかった. この説明で初めて事前確率
という概念が登場し, パラメータにどう影響するかが示唆された.
現実では, この事前確率に対処する方法は様々である. 事前確率が各ラベルで均等である, つまり訓練データ内に均等な頻度で登場しているならあまり気にする必要はないが, 不均衡である場合はナイーブベイズモデルであったり, データのリサンプリングによって補正したりといった応用方法がある.
先日とある企業の面接でロジスティック回帰が話題になり, その際に多クラス分類や多項ロジットに拡張してもこれらは同じなのかという疑問が生じたので追記する. 以下のように, 定義が微妙に異なるものがいくつかあるのでその場では即答できなかったが, 教科書に書かれている内容から容易に導ける話ではあるため追記する. これ以降, ロジットモデルあるいはロジスティック分類について, 3択以上, あるいはクラスが3つ以上の場合を考える. 2択であれば通常のロジットと同じで, 1択や0択やマイナス択は意味をなさないからである. 選択肢を 計量経済学の教科書では, 目的変数がカテゴリカルなモデル全般を扱う分野を離散選択 (discrete choice) と呼んでいる. 多項ロジット (MNL) モデルでは, 選択確率を天下り的に(?) 以下のように決める. ここから, 対数尤度は, ロジットモデルと同様に選択確率の積で以下のように表現できる. 先ほどの選択確率は, 機械学習の教科書では正規化指数関数またはソフトマックス関数と呼ばれる事が多い. つまり, 多項ロジットは機械学習でいう多クラスロジット分類や, ソフトマックス回帰と呼ばれるものと同じである. 実は, この選択確率とかソフトマックス関数とか呼ばれるこの式は, ボルツマン分布またはギブス分布と呼ばれている分布の各パラメータを1に固定した場合と同じである. 私は物理学には詳しくないため, 統計力学でこの式にどのような意味付けがなされているかの解説はしない. ここで, しかし, 計量経済学の文脈では, ロジットの場合と同様に潜在変数アプローチによる説明も重要になる. McFadden (1974) は次のような定式化を提案している. 選択肢が3以上の場合, どの選択肢を選ぶかは よって, よって, この定式化も同じ尤度関数となる. 次に, GLMの場合はどうなるかである. 私はGLMに関する網羅的な教科書を持っていないため, 具体的に参考になる教科書は引用できない. しかし, 多項分類はベクトルGLMとして定式化できるようだ. 多項ロジットと同様に, 事後確率からの多クラスロジスティック回帰はPRMLで言及されている. クラスの事前確率 この時, 最後に, マージンと損失による定式化を多クラス分類に拡張した場合を考える. 多クラス分類の場合のマージンを説明している教科書は見つからなかった. 杉山 (2013) がヒントを示している程度である. ガンベル分布の仮定を追加してよいのなら, 2値の場合と同様に, 損失関数の最小化と尤度の最大化が等価であることは簡単に示せる. 確率分布の仮定を使わない場合は, ソフトマックス関数が, 以上から, 多項ロジット・多クラス分類に拡張しても, 少なくとも3通りの表現は同じモデルに帰着することが, 標準的な教科書からわかる. 計量経済学では, パラメータの推定に関心があることが多い. 既に言及したように, ソフトマックス関数ではパラメータが一意に決まらないため, いずれかの選択肢を基準として, そのパラメータをゼロに固定する. 教科書では, 一方で, 機械学習では回帰係数の一意性が重視されないことが多いため, ライブラリでもこのようなパラメータの正規化がなされない事が多いため, 「多項ロジット」と「多クラスロジスティック」の実装ではそれぞれ結果が異なる可能性がある. 加えて, 多項ロジットとMcFaddenの定義は微妙に異なる. 前者は さらに, scikit-learn では, 特徴量ごとに共通の係数パラメータが設定されているため, 計量経済学におけるMNL設定とは異なり, むしろ条件ロジットと同じ設定になっている. 機械学習寄りの教科書の多くでも, 条件ロジットを想定した表記となっている. だが, クラスの種類がさほど多くないなら, あるクラスに属しているかどうかのバイナリ変数
(追記) 多項選択・多クラス分類への拡張
と書く.
の場合は, 選択確率は
となる. しかし, これはパラメータが過剰であり, 一意にならない. そこで,
で正規化すれば, 2値のロジスティック回帰と同じ式が現れる. よって, 2値のロジット/ロジスティック回帰は多項ロジットの特殊形とみなせる.
で表せる. この時,
が
について互いに独立な標準ロジスティック分布であると仮定するなら, それらの最大値である
はいわゆる順序統計量であり,
の分布はそれぞれ互いに独立な第I種の極値分布あるいはガンベル分布に従う7と仮定する. ガンベル分布は以下のような累積分布関数で表現できる.
の選択確率は
になる. ガンベル分布の累積分布関数と確率密度関数をそれぞれ
とすると, この確率は以下のように周辺化して表せ, そこから再びボルツマン分布が現れる. Train (2009) の3章末にこの導出過程が詳しく書かれている.
に対して線型予測子を定義する.
個の方程式に対してそれぞれソフトマックス関数
を適用すれば, 二項ロジットモデルと同様の選択確率を得られる. ここでも, 各
の場合だけを考えると, 尤度関数は計量経済学の教科書で言うMNLと同じであり, 2値ロジスティック回帰が多項ロジットの特殊形であることも同じである.
に対する事後確率は以下である.
とすると, 上記の事後確率の式はソフトマックス関数となる. そして,
を多変量正規分布と仮定すると,
は
の線形関数となる. PRMLは原著が無料で公開されているため式は省略する.
演算子を滑らかな関数で近似したものであることを利用すれば, 多項ロジットと同じであることを示せそうだが, 少し長くなりそうなので今回は諦めた.
より実用的な観点からの補足
を基準選択肢として, 一般性を失わずに, 以下のように表されることが多い.
で, 後者は
である. つまり, 前者は各選択肢
に対して異なるパラメータと, 同じ説明変数が対応し, 後者は逆に選択肢ごとに値が異なり, パラメータは固定されている. 個人ごとに属性が異なる場合は, 前者の多項ロジットが当てはまるだろう. 後者のような, 説明変数が選択肢ごとに異なる具体例として, 商品の購入行動がある. どの商品を購入するかで価格が異なる場合がある. そのため McFadden の定式化は, 多項ロジットと区別するため条件ロジット (Conditional Logit) と呼ばれる事がある. さらに, 個体ごとに異なる説明変数の項
を追加し, 条件ロジットとMNLの両方のパラメータ化を併用できる, 混合ロジット (Mixed Logit) も存在する. しかし, これらの違いは計画行列の取り方の問題なので, どちらかが潜在変数アプローチに反することはなく, 尤度関数を構成する分布族に本質的な違いも生じない. 結局は各選択肢は互いに素であるため, 尤度関数は, 通常の多項ロジットモデルと同様にボルツマン分布の積で表現できる.
と
次元の特徴量に対して
通り (あるいはパラメータを一意にしたいなら,
) の積を特徴量として用意すれば, MNL・混合ロジットと同等のモデルを計算できないこともない.
参考文献
Bishop, Christopher M. 2006. Pattern Recognition and Machine Learning. Information Science and Statistics. New York: Springer. https://www.microsoft.com/en-us/research/people/cmbishop/prml-book/.
McFadden, Daniel. 1974. “Conditional Logit Analysis of Qualitative Choice Behavior.” In Frontiers in Econometrics, edited by Paul Zarembka, 105–42. New York: Academic Press. https://doi.org/10.1108/eb028592.
Train, Keneth. E. 2009. Discrete Choice Methods with Simulation. 2nd ed. New York: Cambridge University Press. https://eml.berkeley.edu/books/choice2.html.
Wooldridge, Jeffrey M. 2010. Econometric Analysis of Cross Section and Panel Data. 2nd ed. The MIT Press. https://mitpress.mit.edu/books/econometric-analysis-cross-section-and-panel-data.
- GLMに限定して解説している教科書を他には持っていないが, 私が持っている書籍の範囲では, どれもおおむね同じ定義になっている.↩︎
- この説明はあまり正確ではない. それならなぜロジットという別の呼び名があるのか. ロジットとは, ロジスティックシグモイド関数の逆関数を指す. つまり, ロジットリンク関数という名称は, 本来は逆に確率から線形予測子へと変換する関数を意図している.↩︎
- 教科書によっては二項回帰モデルと呼ばれていることもあるが, 多くの教科書ではこれがロジスティック回帰モデルと呼ばれている↩︎
- ここでは, 観測個体ごとに事象がIIDと仮定している. GLMは仮定を緩和しGEEへと拡張することも可能で, 他の分野で使われるロジスティック回帰でもそれぞれ拡張モデルが研究されている. しかし, ここでは一番単純なIIDを想定して比較する.↩︎
- 中川 (2015) でもこちらの定式化に少し触れている.↩︎
- ここでは, z を省略している. z を含めて表現する場合は正規分布が多変量正規分布となるが, やはりパラメータと特徴量ベクトルの線型結合の関数が得られる↩︎
- 英語版Wikipediaでは「標準」ガンベル分布と表記され, 位置パラメータと分散パラメータで標準化していないものを「一般化」ガンベル分布と呼んでいる.↩︎