概要
- これは初心者向けの話
- R の関数に
f(x, ...)のように...という引数があると任意の引数を与えられる - 逆にいえば引数名をタイプミスしてもエラーにならず, 誤りに気づかない
- 久々にこれに引っかかった. みなさんもよく確認して使おう
- もともと上記の問題に関して日記みたいな内容ですますつもりだったが他の事例も書き足しているうちにアンチパターン集みたいなのが本編になってしまった
- データ分析のコードを走らせてエラーが出なかったというだけでは、コードの正しさの保証にはならない
- パッケージのバグ, 言語の特性, 理論的背景の理解不足などいろいろなことが原因でミスが起こるので常に確認を怠らないようにしようというお説教
ことの顛末
先日 R-wakalang で, 「ある本のサンプルコードを参考に回帰モデルの結果をグラフに表してみたがうまくいかない」という質問があった. ここで言及してしまうことで結果としてミスした質問者をさらし者にしてしまう形になるが, 「初歩的なミス」をしていた点では私も同罪なので笑い物の対象にするならば私の方を選んでほしい.
https://r-wakalang.slack.com/archives/C0G1TD69Y/p1627015769009300
質問者はある本のサンプルコードを参考にグラフを描こうとしたができなかった. 具体的には brms パッケージを使ったグループ効果を含む回帰モデルの推定と, その限界効果を marginal_effect() 関数を使ってグループごとに図示する操作をしたが, グループ別のグラフ描画がなぜかできないということだった. 結局, グループ別に表示を指定するために必要な引数 conditions をタイプミスしていたのが原因だったのだが, 私はバージョンの違いではないかとか, この関数は古いので conditional_effect() を使うべきだとか, この原因を特定できずに回答し, 最終的に質問者自身が誤りに気づいて終息した. conditional_effect() を使うべきだというのは今回の問題に関係なく正しいと思っている. さらに言うならば, 私は最初の回答で原因とは直接関係ない別の部分のタイプミスには気づいていた. 意図しない誤誘導に引っかかったということか. サンプルコードとしてはこんな感じになる.1
require(brms) require(tidyverse) require(patchwork) options(mc.cores = parallel::detectCores()) set.seed(42) foo <- expand_grid(ID = LETTERS[1:5], data.frame(obs = 1:10, indiv_eff = rnorm(n = 10))) %>% mutate(fuga = rnorm(n = n()), piyo = rnorm(n = n()), hoge = rpois(n = n(), exp(fuga + piyo + rnorm(n = n(), mean = indiv_eff)))) model <- brm( formula = hoge ~ fuga + piyo + (1|ID), family = gaussian(), data = foo, prior = c(set_prior("", class = "Intercept"), set_prior("", class = "sigma") ), seed = 42 ) g1 <- conditional_effects( model, effects = "fuga", re_formula = NULL, condtions = dplyr::select(foo, ID) %>% distinct(ID) ) g2 <- conditional_effects( model, effects = "fuga", re_formula = NULL, conditions = dplyr::select(foo, ID) %>% distinct(ID) ) plot(g1, plot = F)[[1]] | plot(g2, plot = F)[[1]]
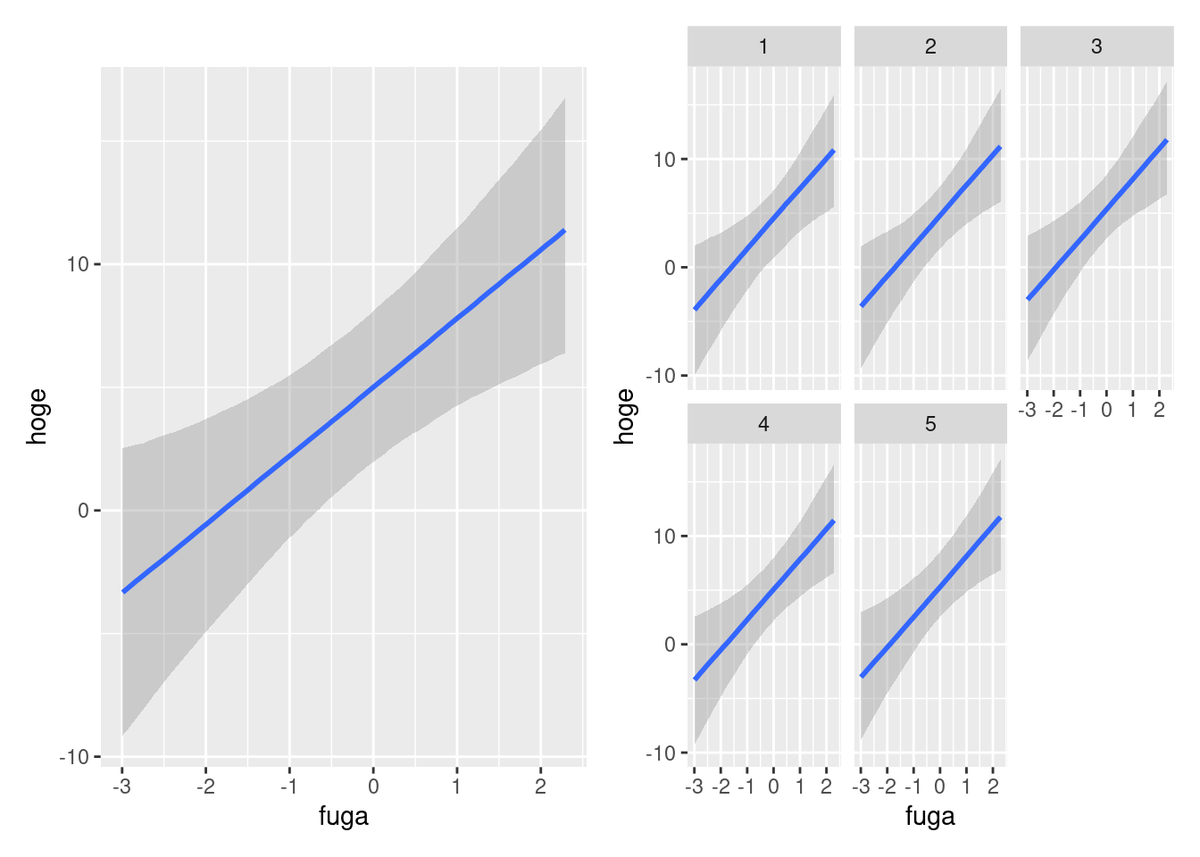
反省会
ではなぜタイプミスという初歩的なミスを見逃したのかというと, その原因は ... というドットを3つ並べた R の特殊な引数にある. これは任意の引数を与えることができることを意味する. Python でいえば *args, **kwargs と同等の機能である. この引数があることで他の処理のラッパだったり, 複数の関数を継承2する際に, 必要な引数を繰り返し書かずにすむので便利である. なおヘルプは ?"..." または ?dots で, ..1 や ...names() など 関連する予約語/関数も含め見ることができる.
しかし, 一方で今回のように引数名を誤って指定した場合, エラーは発生しないし, 同時に (正しく指定したつもりの) 引数は認識されず, 誤りに気づくことすらできないということが起こりやすい. 実態として, 引数名の書き間違えまで気を回してくれるパッケージ開発者はまれである.
そもそも間違っていることに気づきにくい場合
最後に, この問題から飛躍した話をする. 今回は conditions が正しく指定されていないとプロットが分割されないため, 質問者は問題があることにはすぐ気づけたが, グラフの描画や回帰分析の結果は出力を見て結果をそのまま受け入れるということに, 特に操作に慣れない人や内部のメカニズムに明るくない人はなりがちであり, 問題を見落とすおそれがある. いくつか例を挙げる.
ggplot2 でカテゴリごとの色を自分で指定したい
これも初心者の質問としてよく見かける. scale_color_manual() という関数で可能だが, 構文に気をつけないとどの値がどの色に対応するかを誤って指定する可能性がある3 (自分の好みでの色指定はなるべくやらないようにと日頃言っている理由の1つ).
例として, palmerpenguins パッケージのペンギンデータを使ってみる. 以下のように種ごとに色分けする
require(ggplot2) # v3.3.5 require(palmerpenguins) # v0.1 ( g <- ggplot( penguins, aes(x= bill_length_mm, y = body_mass_g, color = species) ) + geom_point() + labs(x = "嘴峰長 (mm)", y = "体重 (g)") )

では, ここで色を palmerpenguins 公式の作例のように, ジェンツーペンギン = シアン, ヒゲペンギン = 紫, アデリーペンギン = darkorange というふうに色を変え, かつ凡例も日本語表記にしてみる.
# 間違った書き方 g + scale_color_manual( values = c("cyan4", "purple", "darkorange"), labels = c("ジェンツー", "ヒゲ", "アデリー") ) + labs(title = "間違ったグラフ", color = "種")

色と名前は変えられたが, 元のグラフと比べると, 対応するペンギンの名前が完全に誤っている. これは scale_color_manual() のラベル名と色の設定が, データに現れた順に割り当てられているからである. よって, 元データを arrange() や filter() で加工しただけでも誤ったグラフを表示してしまうおそれがある. 元データの並びに依存しない書き方として, 下のように元の値を要素名として与えた名前付きベクトルで指定する方法がある4.
g + scale_color_manual( values = c(Gentoo = "cyan4", Chinstrap = "purple", Adelie = "darkorange"), labels = c(Chinstrap = "ヒゲ", Gentoo = "ジェンツー", Adelie = "アデリー") ) + labs(title = "正しく設定できたグラフ", color = "種")

iris や mtcars のような見慣れたデータセットなら間違えても気づきやすいが, 未知のデータセットがどう見えるのかの確認を怠れば間違ったグラフを示すおそれがある. あなたは scale_color_manual() の正しい構文を暗記しているだろうか? 私はめったに使わないのでたまに使う機会があるとそのたびに確認し直している.
これは構文を間違えると大変なことになるという例である. しかし正しい構文で書いたときでさえ, バグでうまく行かない可能性だってある. 次はそういう例.
(Python) seaborn の箱ひげ図が外れ値を表示しなかった (過去形)
これは R ではなく Python の seaborn モジュールに昔 (おそらく v0.6 以前) 存在したバグである. しかし, 「説明書通りに書いたから表示されたグラフも正しいと信じ切っているとハマる好例」なのでここで紹介する. 実際, 当時このバグがあるにもかかわらずこのコードを使ったグラフ作成例を紹介したページを見たことがある.
以下のコードは Python 3.7.5, seaborn v0.6, で実行した. seaborn が v0.7 以降ならば発生しないだろう. おそらく pandas v0.25, matplotlib v2.0.0, numpy v1.20 前後でないとこのバージョン自体動かないので, これらを更新していたら seaborn も一緒に更新している可能性が高い.
import seaborn as sns tips = sns.load_dataset("tips") p = sns.boxplot(x=tips["total_bill"]).set_title(f'seaborn v{sns.__version__}') p.figure.savefig(f'sns-{sns.__version__}.png')
これの実行結果は, v0.6 が左, 最新の v0.11.1 が右になる. このように, seaborn の古いバージョンでは外れ値が表示されないという不具合があった,
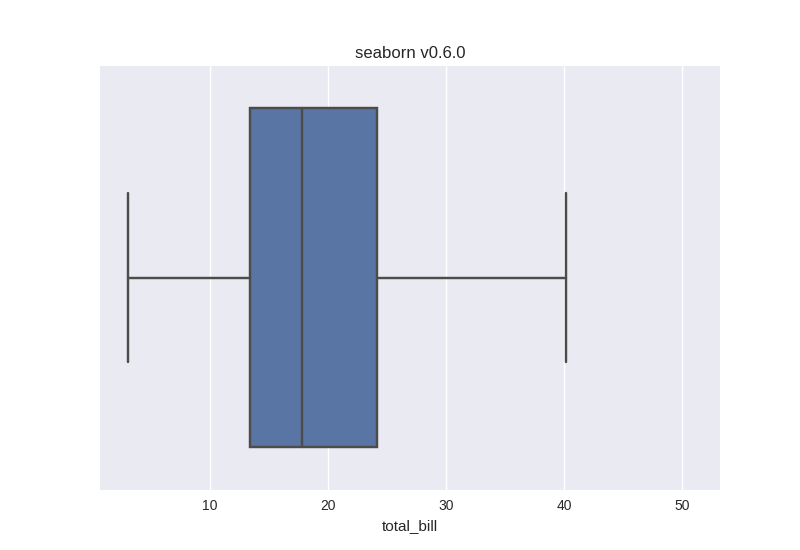
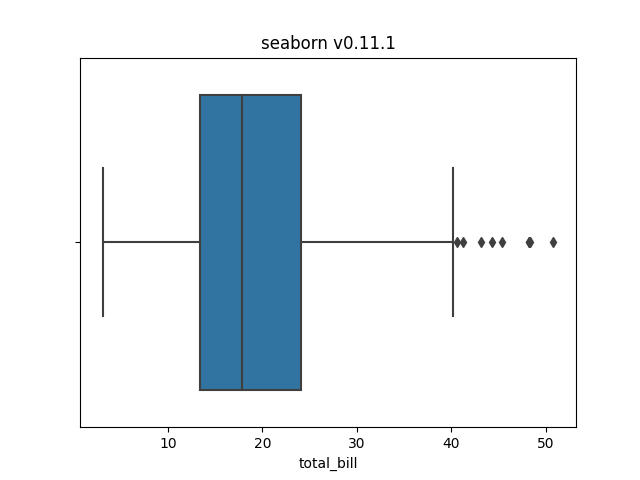
なお現在の公式ドキュメントも, v0.11.1 と同じように外れ値が表示されている
https://seaborn.pydata.org/generated/seaborn.boxplot.html?highlight=box#seaborn.boxplot
これは更新でデフォルトの挙動が外れ値を表示するように変更されたというのではなく, 古いバージョンでは不具合で外れ値が表示されないということである.5 念の為 tips も新旧のバージョンで比較したが, 全く同じデータセットだった. すでにかなり前に修正された問題のため正確な原因は覚えてないが, seaborn のテーマや matplotlib のロードが関係して発生するバグだったと記憶している.
また, バグとユーザの誤解のどちらの原因に帰するか判断が分かれそうな例であるが, 先日紹介した ggplot2 の日付・時刻の扱いも, 正常にグラフが表示されないことがあるため類似の罠だと思う.
estimatr パッケージの統計量の表示がおかしい.
グラフの例を2つ挙げたので, 仕組みを知らないとハマる例も挙げてみる (グラフのほうもある意味「仕組み」を知っているかどうかなので厳密に分けられるものではないとは思う).
これは少し前にも twitter で投稿した話で, github の開発版では修正された (というか私が修正した6) が, 現時点の最新リリース版 (v0.30.2) では未修正の不具合である. estimatr パッケージは二段階最小二乗法など回帰モデルの応用手法をいろいろ提供してくれる便利なパッケージで, すでに利用している人も多いだろうが, iv_robust() 関数で推定した結果について, glance() 関数で1段階目の誘導方程式に関する検定統計量 (弱相関操作変数の検定, 内生性の検定, 過剰識別の検定) が正しく表示されないという問題があった (summary() ならば表示可能). この例はまったくデタラメな値を出すのではなく NA と表示するので, 実装のほうに問題があるということに気づきやすいが, それなりにこのパッケージを使っている人間がいると予想されるのに最近まで話題にならなかったという事実は個人的に気になる. というわけでちょっとこじつけっぽいかもしれないが7, 二段階最小二乗法がどういうしくみなのかを理解していないと, NA が表示されているが, さして重要でない数値だと思って見落としていたかもしれない. そういうわけでこれは, 「何を表すものか知っていないと問題があることに気づかない」例である.
具体例を解説するのが面倒になってきたので他にも箇条書きで簡単に例を書いてみる. わかる人はわかるはず.
追記: これらは私が想定した正解はあるものの, それ以外の回答は不正解ということではない. こういう例を通じて, 必ずどこかにミスがありうるのだと用心する習慣をつけてほしいというのが意図なので, 思考や議論が重要だと考えている. 特に一番最後は状況設定が曖昧なので自分が実際に経験した作業を元にして補うなどする必要があるだろう.
- ある変数の1日前の値を比較したくて
lag()を使用してラグ変数の列を作ったところ, 全期間で全く変化がないという結果になった. (ヒント:dplyrは使っていない) - 追記: 早くも回答者が現れた: Rの `{stats}`の`lag()`の挙動に関する問題(別に問題でもなんでもない) - 備忘ログ - 回帰モデルの一般化逆行列が特異 (= 完全多重共線性がある) である場合, 最小二乗法では係数を求められない. しかし最尤推定とみなしてニュートン法などを使うと, 結果自体は得られる. これは何を意味するのか? その結果を使用しても良いのか?
- R の
lm()の場合は特異でも結果が出てしまうことがある. この挙動を説明できるか?
- R の
- 予測モデルを作って予測残差をプロットしたところ, 分布が偏っていたので, 目的変数を
log(y) ~ .のように対数変換 すればうまく当てはまりそうだと考えやり直してみた. しかしpredict()で得られた予測値の RMSE を計算したところ, 以前よりかなり大きな値が出たため対数変換に効果がないと考えた. (これは回答に複数のパターンがありうる)
最後に
このように統計学や機械学習の理論的背景も, ライブラリの実装やプログラミング言語の特性についても知っていなければハマる落とし穴はたくさんある. しかしこういった問題は Python や R や「データ分析」に限った話ではない. プログラミング全般に言えることで, どう動くのが正しいのか使用者が分かっていなければ (または要件定義や設計で正しいものが何であるか決めなければ) 正しいかどうかのテストのしようがない. こういう意味では, AI (人工知能) とか「データ分析の自動化」などと呼ばれるものも少なくとも現在はまだ, ただ待っているだけで「正しい」結果を出してくれたりするほど高性能にはなっていないことに注意しなければならない. こういうふうに書くと紋切り型のAI批判っぽい言い方に聞こえそうだが, 別の言い方をするならこうだ: R (あるいは Python) はデータの加工やグラフ作成, あるいはモデリングに関してユーザに便利なインターフェイスを提供しアルゴリズムの実装を共有してくれるので, 実装の手間を大幅に減らすことにつながる. しかしバグや仕様変更が完全になくなることはないし, コード資産は共有してくれても専門知識まで共有してくれるわけではない.8
実際にはこの設定ではそもそもグループ別に表示する必要がないことに注意↩︎
プログラミング用語としてはこれを継承と呼ぶのは不正確だが便宜上こう書いた↩︎
参考: スタックオーバーフローでの回答 ↩︎
公式でも名前付きベクトルを使わないサンプルコードを掲載しているが, 正直良くないと思う↩︎
ただし一般論として, ソフトウェアによってはデフォルトで外れ値が表示されなかったり, ヒゲの定義が違ってたりするので, やはりマニュアルを読むのは最低限必要である.↩︎
たとえば tidymodels パッケージのような開発が盛んでかつ最近よく宣伝されてるものをあら捜しすれば (性格が悪い!) 取り上げるのにより適したなにかが見つかるのかもしれないが, 私はほとんどこれを使っていないのでかりに不具合があっても気づかない.↩︎
じゃあどの程度の知識まであればいいのかというと, 得られる知識には際限がないので難しい.↩︎